В. Конорев
Наконец-то договор на проведение маркетингово исследования подписан обеими заинтересованными сторонами, согласована и также подписана программа исследования - пора приступать к работе.
Первый и наиболее важный этап в работе - доработка макета опросного листа (анкеты) и его утверждение Заказчиком.
Основные требования к содержанию опросного листа (анкете):
При разработке опросного листа особенное внимание должно уделяться выбору вопросов, по которым впоследствии будет осуществляться оценка репрезентативности полученной в результате опроса информации (РЕПРЕЗЕНТАТИВНОСТЬ - применительно к маркетинговым исследованиям означает проверку гипотезы о том, что количество опрошенных
респондентов вполне достаточно (статистически значимо) для объективной оценки ситуации на исследуемом рынке товаров и услуг).Так при проведении опросов населения города к подобным вопросам можно отнести: “Ваш возраст”, “Ваш пол” и “Какое у Вас образование”. Это объясняется тем, что в справочниках Ленинграда 80-х годов можно было наити информацию о распределении населения города по возрасту и уровню образования, что и использовалось автором статьи при определении репрезентативности информации. К настоящему
времени автору известны только данные о количестве граждан, соотносимые к полу и возрасту и почерпнутые из сборника: “За строкой цифр. С.-Петербург 1995 г.”, раздел “Демография”, таблица 17, “Возрастной состав постоянного населения (на 1 января 1995 г.)”.В соответствии с данными таблицы были пересчитаны процентные отношения для анкетируемых категорий граждан. Данные представлены в процентах относительно возрастной категории “16 лет и старше” для обоих полов и представлены в Таб. 1
Таб. 1
Возраст (лет) |
|||||||
Пол |
16-19 |
20-24 |
25-34 |
35-44 |
45-54 |
55-69 |
Старше 70 |
Мужской |
3,20% |
4,67% |
9,35% |
9,27% |
6,50% |
8,55% |
2,35% |
Женский |
3,14% |
4,23% |
9,19% |
11,20% |
7,83% |
12,84% |
7,68% |
Применительно, например, к начальной оценке в 500 респондентов количество их в каждой из групп рассчитаны и представлены в Таб. 2.
Таб. 2
Возраст (лет) |
|||||||
Пол |
16-19 |
20-24 |
25-34 |
35-44 |
45-54 |
55-69 |
Старше 70 |
Мужской |
16 |
23 |
47 |
46 |
32 |
43 |
12 |
Женский |
16 |
21 |
46 |
56 |
39 |
64 |
39 |
По мере поступления от интервьюеров заполненных респондентами анкет информация кодируется и вводится в информационную базу с последующим расчетом фактического распределения данных по возрастным категориям. В соответствии с данными Таб. 2 бригадир, отвечающий за сбор информации, постоянно сравнивает количество фактически опрошенных респондентов по каждой из групп с заданным и корректирует задания по сбору информации интервьюерам. В разработанном автором программном обеспечении по результатам ввода очередной порции массива анкет выводится информация об отклонении фактического количества анкет от заданного, величина которого также может корректироваться, по всем возрастным категориям, что достаточно удобно для практической работы. Этот этап исследования, связанный со сбором информации характерен для опросов населения всего исследуемого региона, например
города, с целью выявления мнения населения к тем или иным продуктам питания, к продукции, производимой крупной фирмой и так далее.В случае опросов представителей торговых предприятий о качестве поставляемой для продажи продукции, информация о количестве торговых предприятий в исследуемом регионе по видам торговой деятельности (продовольственный магазин, овощной магазин, молочных магазин и так далее), как правило, отсутствует. Кроме того, зачастую в продовольственных магазинах осуществляется порой продажа
парфюмерии, товаров первой необходимости, бытовой радиотехники и так далее. В этом случае можно в качестве исследуемых на репрезентативность вопросов рекомендовать такие, как “Вид торгового предприятия”, “Признак продажи исследуемого товара”, “Товару отечественного или импортного производства Вы отдаете предпочтение” и ряд иных вопросов.Представляется, что здесь у внимательного и любознательного читателя возникнет вполне резонный вопрос; почему автор статьи так подробно останавливается на вопросе оценки репрезентативности полученной информации в результате проведения опроса. По глубокому убеждению автора, оценка репрезентативности является особенно важной, так как недостоверная, нерепрезентативная информация может привести по результатам анализа к недостоверным, некорректным выводам и, как следствие, неверным рекомендациям, что, в свою очередь, может нанести предприятию (фирме) - заказчику исследования весьма ощутимые финансовые потери. Некорректные рекомендации могут выразиться в рекомендациях по снятию с производства определенной продукции, якобы не пользующейся достаточных спросом, либо, наоборот, увеличения производства определенной номенклатуры продукции пользующейся, по мнению проводивших маркетинговое исследование, повышенным спросом. В первом случае,
рынок сбыта продукции может быть “захвачен” предприятием - конкурентом, во втором случае - привести к “затариванию” товарных запасов, то есть “омертвлению” как материальных, так и, опосредованно, финансовых ресурсов.Рассмотрим последовательно процедуры оценки репрезентативности при условии структурированного информационного пространства, например, при опросе населения, и неструктурированного информационного пространства - опрос руководителей различных торговых предприятий:
Таб. 3
Возраст (лет) |
|||||||
Пол |
16-19 |
20-24 |
25-34 |
35-44 |
45-54 |
55-69 |
Старше 70 |
Мужской |
5,40% |
3,24% |
8,17% |
9,24% |
6,40% |
10,21% |
3,21% |
Женский |
4,17% |
5,16% |
10,21% |
9,17% |
8,22% |
10,23% |
6,97% |
Затем рассчитываются величины
отклонений ![]() ) полученных
значений (Таб. 3) от заданных, представленных в
Таб. 1 по формуле:
) полученных
значений (Таб. 3) от заданных, представленных в
Таб. 1 по формуле:
![]() (1)
(1)
где Zi - заданное в Таб. 1 значение процентного отношения по i-й возрастной категории;
Fi - рассчитанное по контрольному массиву процентное отношение по i-й возрастной категории.
Результаты расчета представлены в Таб. 4
Таб. 4
Возраст (лет) |
|||||||
Пол |
16-19 |
20-24 |
25-34 |
35-44 |
45-54 |
55-69 |
Старше 70 |
Мужской |
-0.6875 |
0.3062 |
0.1262 |
0.0032 |
0.0154 |
0.1942 |
-0.3660 |
Женский |
-0.3280 |
-0.2200 |
-0.1110 |
0.1990 |
-0.0498 |
0.2033 |
0.0924 |
Знак (-) означает, что количество респондентов (анкет) в контрольном массиве превышает заданное в соответствии с процентными отношениями, указанными в Таб. 1. Поэтому поиск ведется только по шкалам, в которых коэффициенты имеют положительное значение. Максимальное положительное значение получено для шкалы “Пол мужской, возраст 20 - 24”.
На следующем этапе формирования контрольного массива продолжается вышеуказанным способом, то есть используется датчик случайных чисел, но выбираются только та анкета, респондент которой относится к данному полу (“Мужской”) и данной возрастной категории (“20 - 24 года”). Значения представленные в Таб. 4 рассчитываются заново и вышеуказанная процедура повторяется, то есть определяется шкала, для которой рассчитанный по формуле (1) положительный коэффициент максимален и в контрольный массив вводится также только та анкета, которая относится к данной конкретной возрастной категории. Процедура формирования контрольного массива прекращается по двум причинам (условиям):
Далее производится проверка гипотез равенства средних и дисперсий по выбранным для анализа вопросам для фактического массива анкет и контрольного. В качестве вопросов для анализа должны быть использованы только те из них, на которые отвечают практически все респонденты, например, “Ваш возраст”, “Род Ваших занятий”, “Являетесь ли Вы уроженцем СПб”, “Какое у Вас образование” и так далее.
Проверка гипотезы равенства средних (для независимых выборок) производится с использование следующего критерия:
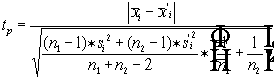 (2)
(2)
где ![]()
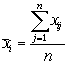 (3)
(3)
![]() - соответственно среднее значение
i-го вопроса для контрольного массива анкет;
- соответственно среднее значение
i-го вопроса для контрольного массива анкет;
![]() - выборочная дисперсия i-го вопроса
для фактического массива анкет и рассчитывается
по формуле:
- выборочная дисперсия i-го вопроса
для фактического массива анкет и рассчитывается
по формуле:
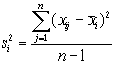 (3)
(3)
![]() - соответственно выборочная
дисперсия i-го вопроса для контрольного массива
анкет гипотеза равенства выборочных средних
принимается, если tp <=t(p,n
) (p=1-a /2), a - 0,05, n = n1 +n2 -2 (a - принятый уровень существенности, n - число степеней
свободы, n1, n2 -
соответственно количество фактических анкет и
количество анкет контрольного примера).
- соответственно выборочная
дисперсия i-го вопроса для контрольного массива
анкет гипотеза равенства выборочных средних
принимается, если tp <=t(p,n
) (p=1-a /2), a - 0,05, n = n1 +n2 -2 (a - принятый уровень существенности, n - число степеней
свободы, n1, n2 -
соответственно количество фактических анкет и
количество анкет контрольного примера).
Для проверки гипотезы равенства выборочных дисперсий (для независимых выборок) используется критерий отношения двух дисперсий, рассчитываемый по формуле:
![]() (4)
(4)
В случае, если ![]() ,, то гипотеза равенства выборочных
дисперсий принимается.
,, то гипотеза равенства выборочных
дисперсий принимается.
Для удобства анализа в разработанном автором программном обеспечении все критические значения (t и F) для заданной вероятности рассчитываются с использованием соответствующих асимптотических формул, частично оригинальных.
Вышеуказанная процедура анализа повторяется не менее 1.000 раз (как показали исследования проведенные автором величина 1.000 является наиболее оптимальной). По каждому из анализируемых вопросов рассчитывается относительное количество равенства средних и дисперсий, то есть, например, в 955 случаях из 1.000 (95.5%) гипотеза равенства средних по первому вопросу подтвердилась. При этом считается,
что если по всем исследуемым вопросам гипотезы равенства средних и дисперсий подтвердились в 95% и более случаях, то полученные в ходе проведения опроса данные являются репрезентативными. В противном случае, необходимо продолжить опрос (анкетирование) респондентов;Для данного случая характерно отсутствие каких-либо заданных значений (пропорций). Формирование контрольного массива из исходного производится также с использованием датчика случайных чисел равномерного распределения. При этом, количество анкет в контрольном массиве может быть наперед заданным и постоянным, либо переменным в заданном диапазоне. В разработанном программном обеспечении реализованы оба варианта. Следует отметить, что по результатам контрольных расчетов не удалось выделить, как лучший, какой-либо из них. Процедура проверки равенсва средних и дисперсий аналогична процедуре, применяемой для условия структурированного информационного пространства.
В следующей статье предполагается описать этапы разработки макета анкеты и некоторые методы организации и приемы проведения опроса респондентов.
Вячеслав Архипович Конорев
.
Только подписка гарантирует Вам оперативное получение информации о новинках данного раздела
Нужное: Услуги нянь Коллекционные куклы Уборка, мытье окон